What will eyegrade 0.6 include? (part 1)
Even though version 0.5 was released just a couple of weeks ago, the next release, 0.6, is approaching. As I did with the previous release, I'll blog about the new features it will include as they are more or less ready.
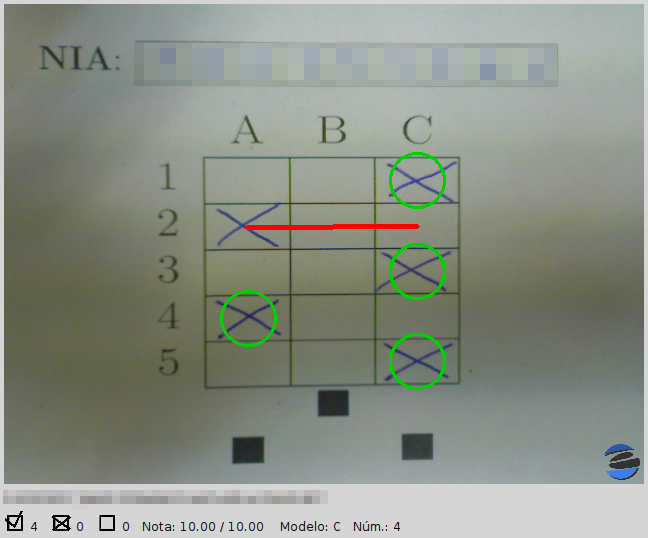
The first feature I'd like to talk about is a new subsystem for recognizing handwritten digits, which replaces the one that I wrote in the early days of Eyegrade. Rodrigo Argüello, a former student of mine at Universidad Carlos III de Madrid, volunteered to improve the previous system with a machine learning based solution. More specifically, he used a support vector machine (SVM). The machine is trained by showing it lots of samples of each digit, and telling it which digit each sample represents. Once trained, you can show an image of a digit to it, and it will answer with the digit it considers the best match for the image.
Rodrigo tried with several strategies before finally integrating one into Eyegrade. Our first tests in real scenarios show that, under conditions in which the former system failed approximately once for every 6 student identifications, the new system fails approximately once for every 20. I believe it is a big step forward. Many thanks to Rodrigo for his great contribution, and to Roberto for sending us tons of samples for training and testing the new system.
Removing the old digit recognition system provides a second benefit: the tre library is no longer needed. The fact that it wasn't a pure Python library, and that it doesn't seem to be widely used from Python, was a headache for deploying the Windows version, and complicated the installation procedure in Linux a little bit. If everything goes as planned, you can expect a greatly simplified installation procedure, especially for Windows users. More on this topic on my next post.